ESM Runscripts - Using the Workflow Manager¶
Introduction¶
Starting with Release 6.0, esm_runscripts allows the user to define additional subjobs for data processing, arrange them in clusters, and set the order of execution of these and the standard runjob parts in a flexible and short way from the runscript. This is applicable for both pre- and postprocessing, but especially useful for iterative coupling jobs, like e.g. coupling pism to vilma (see below). In this section we explain the basic concept, and the keywords that have to be set in the runscript to make use of this feature.
Subjobs of a normal run¶
Even before the addition of the workflow manager, the run jobs of esm_runscript were split into different subjobs, even though that was mostly hidden from the user’s view. Before Release 6.0, these subjobs were:
compute --> tidy_and_resubmit (incl. wait_and_observe + resubmit next run)
Technically, wait_and_observe was part of the tidy_and_resubmit job, as was the resubmission, including above only for the purpose of demonstrating the difference to the
new standard workflow, which is now (post-Release 6.0):
newrun --> prepcompute --> compute --> observe_compute --> tidy (+ resubmit next run)
Other than before adding the workflow manager, these standard subjobs are all separated and independant subjobs, each submitted (or started) by the previous subjob in one of three ways (see below). The splitting of the old compute job into newrun, prepcompute and compute on one side, and tidy_and_resubmit into observe and tidy, was necessary to enable the user to insert coupling subjobs for iterative coupling at the correct places. Here is what each of the standard subjobs does:
Keyword Function ====================================================== ==========================================================
- workflow Chapter headline in a model’s section, indicating that
alterations to the standard workflow will be defined here
- subjob_clusters Section in the workflow chapter, containing the information
on additional subjob_clusters. A subjob_cluster is a collection of subjobs run from the same batch script. Each subjob needs to belong to one cluster, if none is defined, each subjob will automatically get assigned to its own cluster. Each entry in
subjob_clustersis a dict, with the outermost key being the (arbitrary) name of the cluster.- subjobs Section in the workflow chapter, containing the information
on additional subjobs.
- run_after / run_before Entry in spevifications of a subjob_cluster, to define
before or after which other cluster of the workflow this cluster is supposed to run. Only one of the two should be specified. Can also be used in the specifications of subjobs if these subjobs get a corresponding cluster auto-assigned.
script: script_dir: call_function: env_preparation: next_run_triggered_by:
Example 1: Adding an additional postprocessing subjob¶
In the case of a simple echam postprocessing job, the corresponding section in the runscript could look like this:
echam: [...other information...] workflow: next_run_triggered_by: tidy subjobs: my_new_subjob: nproc: 1 run_after: tidy script_dir: script: call_function: env_preparation:
Example 2: Adding an additional preprocessing subjob¶
A preprocessing job basically is configured the same way as a postprocessing job, but the run_after entry is repl
Example 3: Adding a iterative coupling job¶
Writing a runscript for iterative coupling using the workflow manager requires some more changes. The principal idea is that each coupling step consists of two data processing jobs, one pre- and one postprocessing job. This is done this way as to make the coupling modular, and enable the modeller to easily replace one of the coupled components by a different implementation. This is of course up to the user to decide, but we generally advise to do so, and the iterative couplings distributed with ESM-Tools are organized this way.
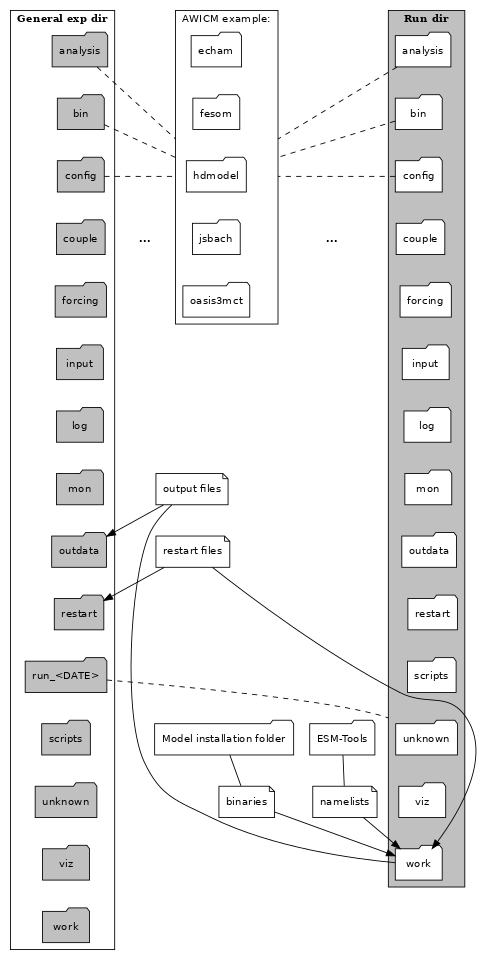
Experiment directory structure¶
Note
Having a general and several run subfolders means that files are duplicated and, when models consist of several runs, the general directory can end up looking very untidy. Run folders were created with the idea that they will be deleted once all files have been transferred to their respective folders in the general experiment directory. The default is not to delete this folders as they can be useful for debugging or restarting a crashed simulation, but the user can choose to delete them (see Cleanup of run_ directories).